Proyecto Redes Neuronales - face2face
El proyecto es un fork de face2face-demo de datitran. Utiliza pix2pix para aprender los rasgos faciales y ponerlos en una cara. Por medio de una webcam o un video, coloca tu rostro en la cara “entrenada” de EPN en tiempo real o no.
Debido al pobre poder de computo de mi laptop, correr el programa en tiempo real fue imposible, así que agregué run_video.py tomado de face2face-demo de karolmajek .
Datos de entrenamiento
Lo primero fue crear un conjunto de datos. Luego se utilizó el Dlib’s pose estimator que puede detectar 68 puntos de referencia (boca, cejas, ojos, etc.) en una cara junto con OpenCV para procesar el archivo de video.
Desde que elegí este proyecto pense en utilizar de modelo a Enrique Peña Nieto (Presidente de México). Buscando videos en YouTube me decidí por el video del discurso que dio cuando acabaron las elecciones para presidente de 2018, ya que me parecio adecuado por que la posición de la cámara estaba estática para obtener muchas imagenes de las mismas posiciones de su cara y el fondo.
Modelo de entrenamiento
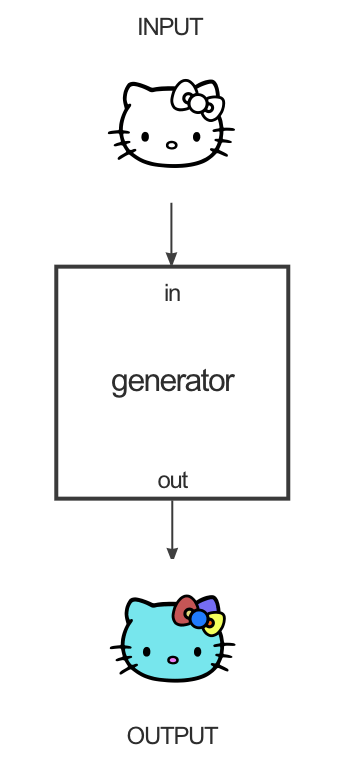
Pix2pix utiliza una red de confrontacion generativa condicional (cGAN) para aprender un mapeo de una imagen de entrada a una imagen de salida. La red cuenta con dos partes principales, el Generador y el Discriminador. El generador aplica alguna transformación a la imagen de entrada para obtener la imagen de salida. El Discriminador compara la imagen de entrada con una imagen desconocida e intenta adivinar si fue generada por el generador. Un ejemplo de un conjunto de datos sería que la imagen de entrada es una imagen en blanco y negro y la imagen objetivo es la versión en color de la imagen:
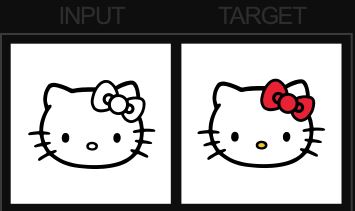
El generador en este caso trata de aprender a colorear una imagen en blanco y negro.
El discriminador esta tratando de aprender a distinguir entre las colorizaciones del generador y la imagen del conjunto de datos.
Generador
El generador tiene la tarea de tomar una imagen de entrada y realizar la transformación que deseamos para producir la imagen de destino. La estructura del generador se denomina “encoder-decoder” y en pix2pix el encoder-decoder es más o menos así:
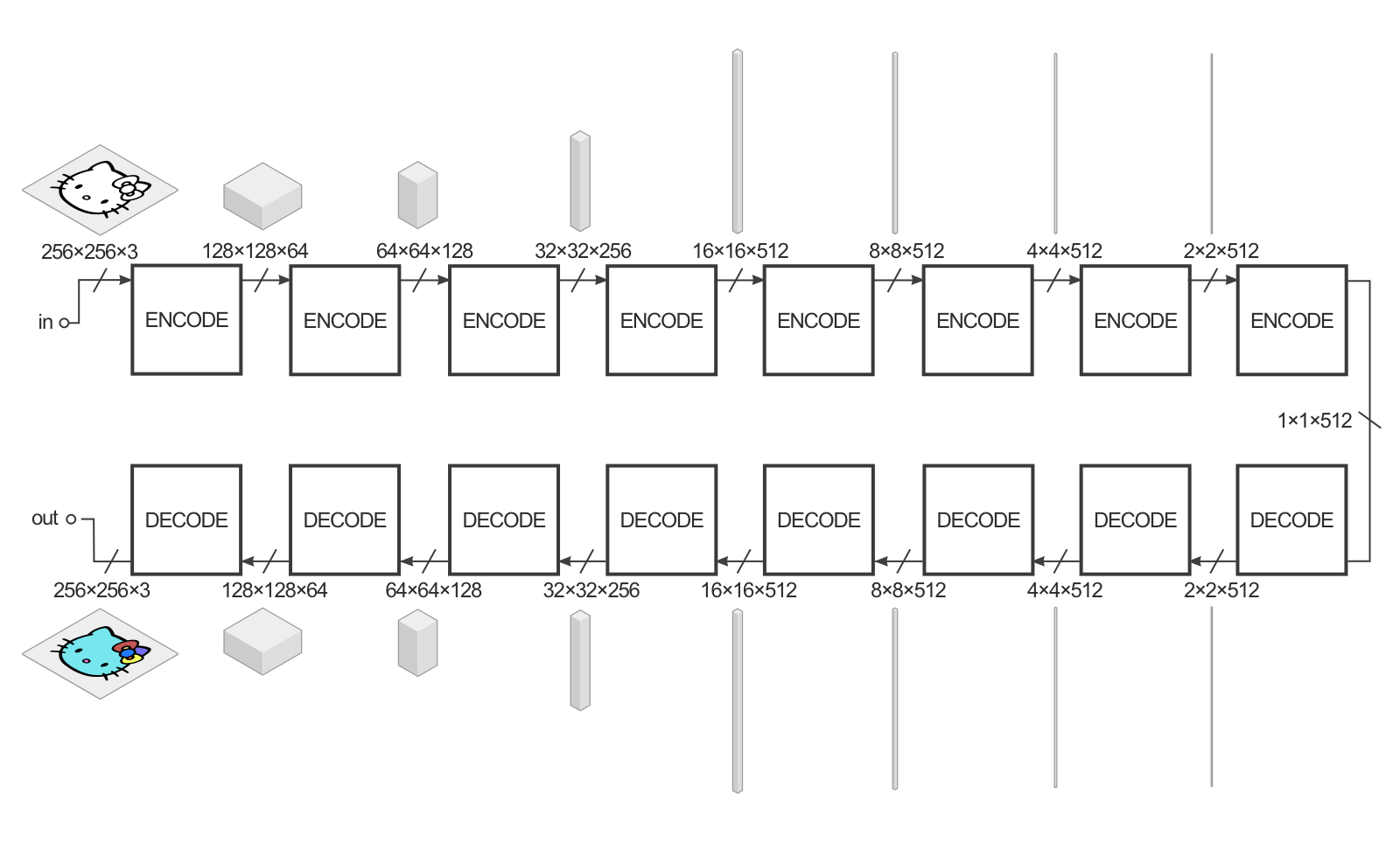
La entrada en este ejemplo es una imagen de 256x256 con 3 canales de color (rojo, verde y azul) y la salida es la misma.
El generador toma algo de entrada e intenta reducirlo con una serie de encoders (función de convolución + activación) en una representación mucho más pequeña. La idea es que al comprimirlo de esta manera, se espera que tengamos una representación de los datos de mayor nivel después de la capa de encoding final. Las capas de decoding hacen lo opuesto (deconvolución + función de activación) e invierten la acción de las capas del encoder.
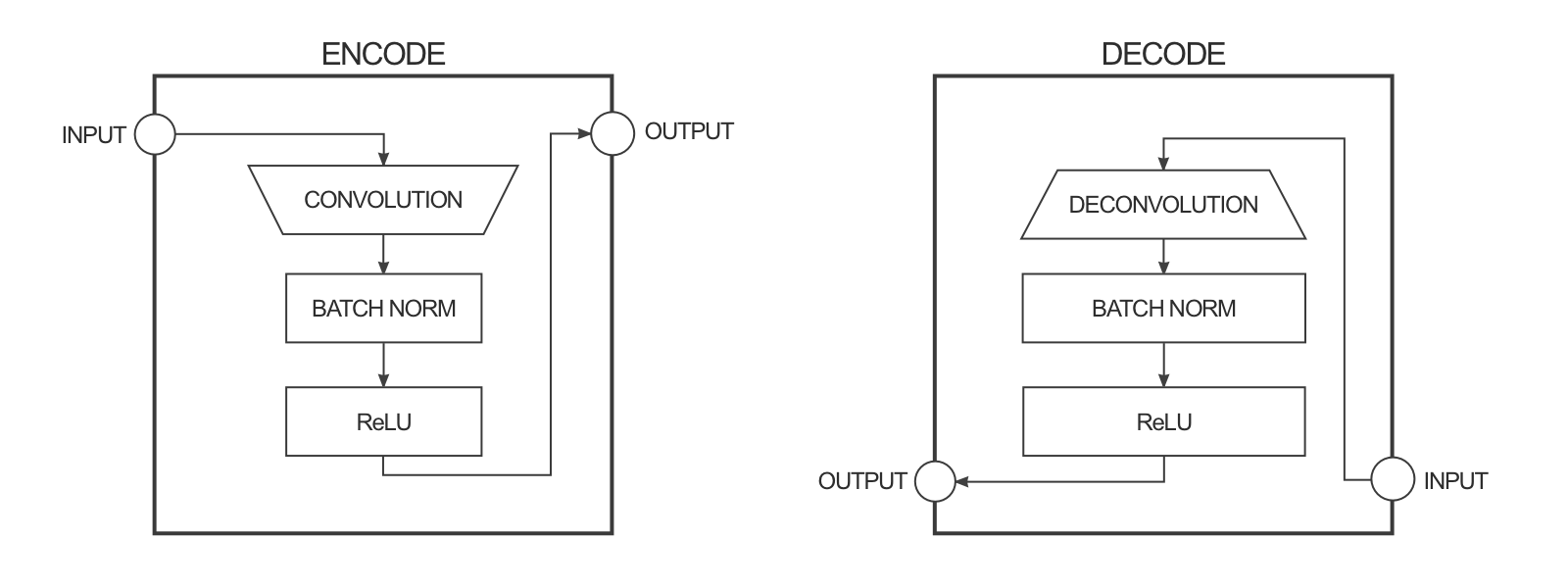
Para mejorar el rendimiento de la transformación image-to-image en el documento, los autores utilizaron una “U-Net” en lugar de un encoder-decoder. Esto es lo mismo, pero con “omitir conexiones” conectando directamente las capas del encoder a las capas del decoder:
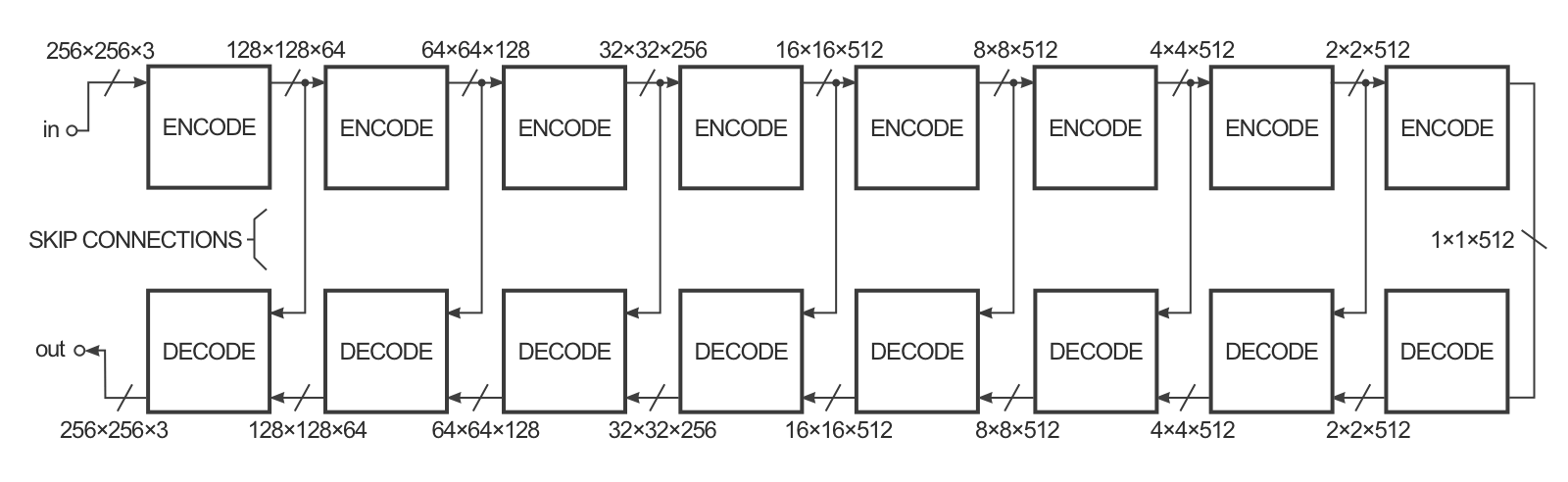
Las conexiones de omisión le dan a la red la opción de omitir la parte de encoding/decoding si no tiene un uso para ello.
Estos diagramas son una ligera simplificación. Por ejemplo, la primera y la última capa de la red no tienen una capa de norma por lotes y algunas capas en el medio tienen unidades de deserción. El modo de colorización utilizado en el papel también tiene un número diferente de canales para las capas de entrada y salida.
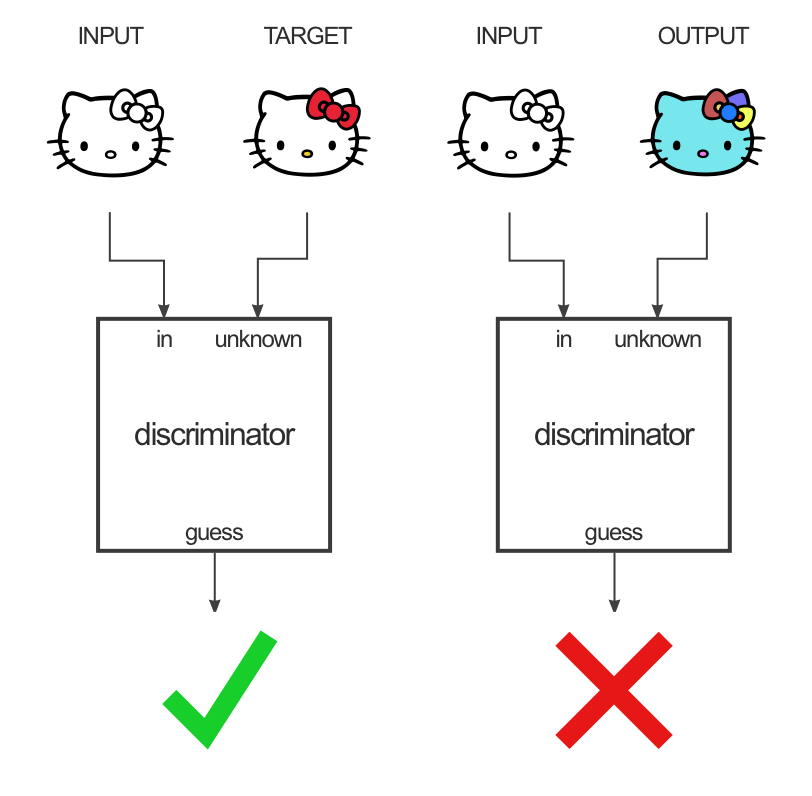
Discriminador
El Discriminador tiene la tarea de tomar dos imágenes, una imagen de entrada y una imagen desconocida y decidir si la segunda imagen fue generada por el generador o no.
La estructura se parece mucho a la sección del encoder del generador, pero funciona de manera un poco diferente.

La salida es una imagen de 30x30 donde cada valor de píxel (0 a 1) representa cuán creíble es la sección correspondiente de la imagen desconocida. En la implementación de pix2pix, cada píxel de esta imagen de 30x30 corresponde a la credibilidad de un parche de 70x70 de la imagen de entrada (los parches se superponen mucho ya que las imágenes de entrada son de 256x256). La arquitectura se llama “PatchGAN”.
Entrenamiento
Para entrenar esta red, se siguen dos pasos: entrenar al discriminador y entrenar al generador. Para entrenar al discriminador, primero el generador produce una imagen de salida. El discriminador mira el par de entrada/objetivo y el par de entrada/salida y hace su conjetura acerca de qué tan realistas se ven. Los pesos del discriminador se ajustan según el error de clasificación del par de entrada/salida y el par de entrada/objetivo.
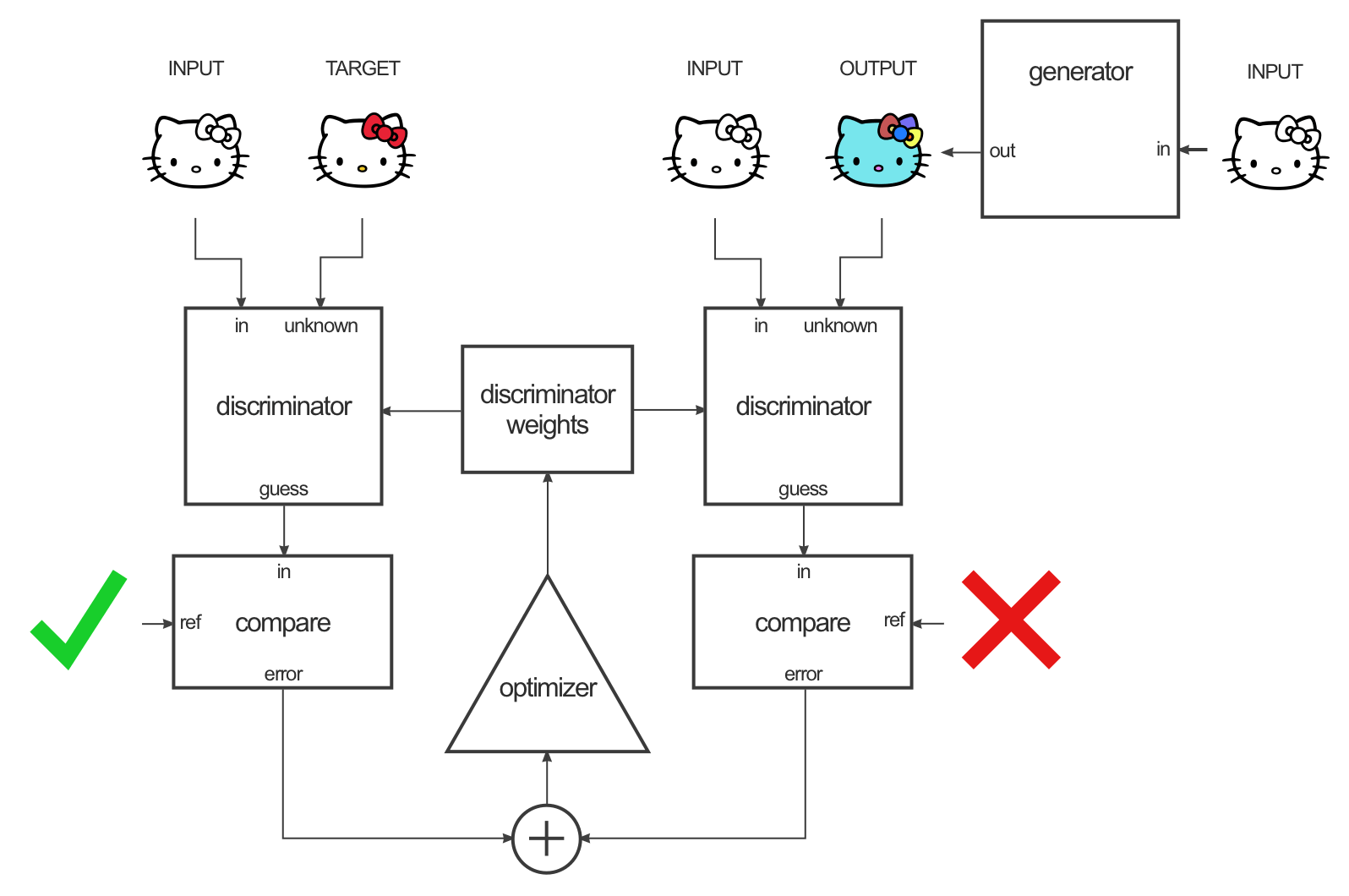
Los pesos del generador se ajustan según la salida del discriminador y la diferencia entre la salida y la imagen objetivo.
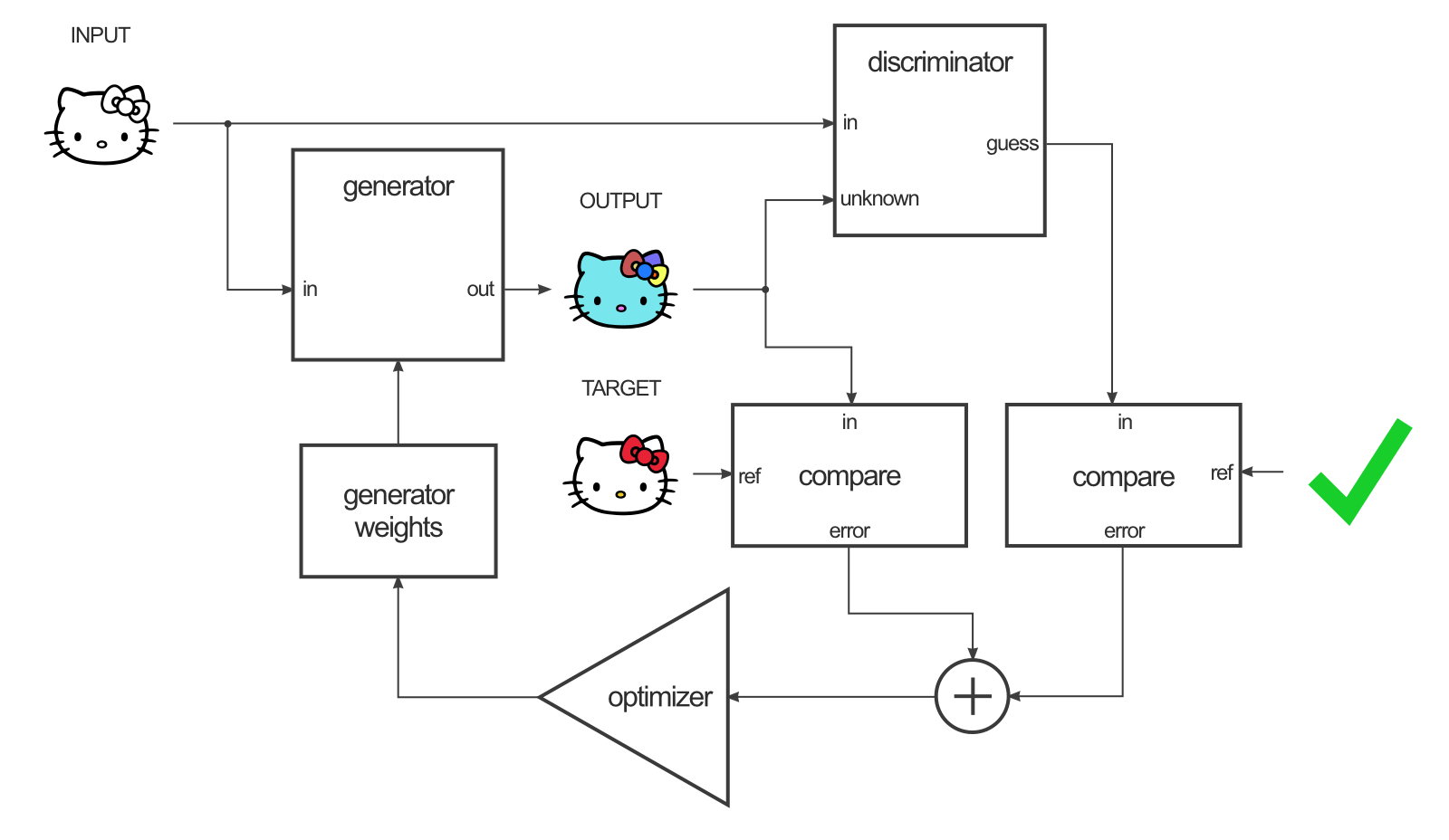
Cuando se entrena el generador en la salida del discriminador, en realidad estás calculando los gradientes a través del discriminador, lo que significa que mientras el discriminador mejora, estás entrenando al generador para vencer al discriminador. La teoría es que a medida que el discriminador mejora, también lo hace el generador. Si el discriminador es bueno en su trabajo y el generador es capaz de aprender la función de mapeo correcta a través del descenso de gradiente, debe obtener salidas generadas que podrían engañar a un humano.
Getting Started
1. Preparando environment
# Clonar est repositorio
git clone git@github.com:datitran/face2face-demo.git
# Crear el environment desde el archivo
conda env create -f environment.yml
# Activar environment
source activat face2face-demo
2. Generar datos de entrenamiento
python generate_train_data.py --file peñaRecorte.mp4 --num 400 --landmark-model shape_predictor_68_face_landmarks.dat
Input:
filees el nombre del video con el que se creara el data set.numes el número de datos de entrenaminto que seran creados.landmark-modeles el facial landmark model usado para detectar landmarks. Un pre-entrenado facial landmark model esta incluido en el repositorio.
Output:
- Dos folders
originalandlandmarksseran creados.
3. Entrenar modelo
# Clonar este repositorio de Christopher Hesse's pix2pix TensorFlow implementation
git clone https://github.com/affinelayer/pix2pix-tensorflow
cd pix2pix-tensorflow
# Reset a la versión de abril
git reset --hard d6f8e4ce00a1fd7a96a72ed17366bfcb207882c7
# Mover al directorio de pix2pix y crear una carpeta para las fotos
mkdir photos
# Mover las carpetas original y landmarks a la carpeta de pix2pix-tensorflow
mv face2face-demo/landmarks face2face-demo/original pix2pix-tensorflow/photos
# Ve al folder de pix2pix-tensorflow
cd pix2pix-tensorflow/
# Redimensionar las imagenes de original
python tools/process.py \
--input_dir photos/original \
--operation resize \
--output_dir photos/original_resized
# Redimensionar las imagenes de landmark
python tools/process.py \
--input_dir photos/landmarks \
--operation resize \
--output_dir photos/landmarks_resized
# Combinar las imagenes de original y landmark
python tools/process.py \
--input_dir photos/landmarks_resized \
--b_dir photos/original_resized \
--operation combine \
--output_dir photos/combined
# Dividir en train/val
python tools/split.py \
--dir photos/combined
# Entrenar el modelo
python pix2pix.py \
--mode train \
--checkpoint name \
--output_dir face2face-model \
--max_epochs 200 \
--input_dir photos/combined/train \
--which_direction AtoB
--save_frequ 50
Christopher Hesse’s pix2pix-tensorflow implementation.
4. Exportar el modelo
- Se necesita reducir el modelo entrenado.
python reduce_model.py --model-input face2face-model --model-output face2face-reduced-modelInput:
model-inputla carpeta del modelo.model-outputla carpeta donde quedará el modelo reducido.
Output:
- Regresa un modelo reducido con un tamaño menor que el original
- Se congela el modelo reducido a un solo archivo.
python freeze_model.py --model-folder face2face-reduced-modelInput:
model-folderla carpeta donde esta el modelo reducido.
Output:
frozen_model.pben la carpeta del modelo.
Pre-trained frozen model Proximamente. Modelo entrenado con 400 imagenes y 200 epoch.
5. Run Demo
Real-Time
python run_webcam.py --source 0 --show 0 --landmark-model shape_predictor_68_face_landmarks.dat --tf-model face2face-reduced-model/frozen_model.pb
Input:
sourceis the device index of the camera (default=0).showmostrar la imagen de la webcam (0) o los rasgos faciales (1) (default=0).landmark-modelfacial landmark model usado apra detectar rasgos faciales.tf-modelel modelo congelado.
NO Real-Time
python run_video.py --source video.mp4 --show 0 --landmark-model shape_predictor_68_face_landmarks.dat --tf-model face2face-reduced-model/frozen_model.pb
Input:
sourcevideo a usar (default=0).showmostrar la imagen de la webcam (0) o los rasgos faciales (1) (default=0).landmark-modelfacial landmark model usado apra detectar rasgos faciales.tf-modelel modelo congelado.
Ejemplo original:

Resultado:

Experiencia
El intentar entrenar en mi equipo de computo fue imposible, cada epoch tardaba aproximadamente 1 hora (o más), ademas mientras entrenaba no se podía utilizar para otras cosas. Fue muy frustrante.
Afortunadamente despues pude realizar el entrenamiento en el [ACARUS: Área de Computo de Alto Rendimiento de la Universidad de Sonora] (http://acarus.uson.mx/) y me fue de maravilla, el entrenamiento termino en aproximadamente 5 horas, lo unico que quedaba era ver los resultados. Aqui vino otro problema, a pesar de tener un lugar donde entrenar mi modelo en poco tiempo, mi computadora apenas soportaba la aplicación de prueba del modelo. Funcionaba extremadamente lento (en el modo real-time era peor). Aun con los problemas con mi equipo de computo los resultados me gustaron y me pareció una gran experiencia.
Para que funcione bien se necesita un buen video de donde obtener los datos. Con el modelo que se proporciona (Angela Merkel) o con el que yo entrené sólo funciona en cierta posición y distancia de la camara.